Absolutely, let’s break this down into manageable parts and start with the basics. Ansible is all about automating tasks, so we’ll begin with the foundational concepts and gradually move to more complex examples.
Part 1: Understanding Ansible Basics
What is Ansible?
Ansible is an automation tool that allows you to configure, deploy, and orchestrate advanced IT tasks such as continuous deployments or zero downtime rolling updates. Its main goals are simplicity and ease of use. It also features a declarative language to describe system configuration.
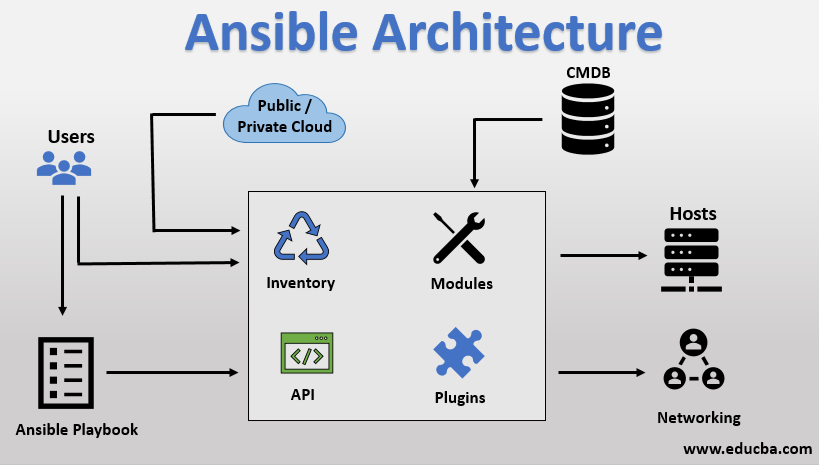
Ansible Architecture
- Control Node: The machine where Ansible is installed and runs from.
- Managed Nodes: The network devices (like servers) you manage with Ansible.
- Inventory: A list of managed nodes. An inventory file is often written in INI or YAML format.
- Playbooks: YAML files where you define what you want to happen.
- Modules: Tools in your toolbox; they do the actual work in Ansible.
- Tasks: The units of action in Ansible.
- Roles: Pre-packaged sets of tasks and additional files to configure a server for a certain role.
- Facts: Global variables containing information about the system, like network interfaces or operating system.
Installation
Here is how you would typically install Ansible on a Linux-based control machine:
# Install Ansible on a Debian/Ubuntu system
sudo apt update
sudo apt install ansible
# Or, install Ansible on a Red Hat/CentOS system
sudo yum install ansibleAnsible Configuration
Ansible’s behavior can be customized via settings in the /etc/ansible/ansible.cfg configuration file. You can specify a different configuration file using the ANSIBLE_CONFIG environment variable if needed.
Ansible Inventory
The inventory file specifies the hosts and groups of hosts upon which commands, modules, and tasks in a playbook operate. The default location for the inventory file is /etc/ansible/hosts.
Here is an example of an inventory file:
# /etc/ansible/hosts
[webservers]
web1.example.com web2.example.com
[dbservers]
db1.example.com db2.example.com
Part 2: Ad-Hoc Commands
Ad-hoc commands are a great way to use Ansible for quick tasks that don’t necessitate the writing of a full playbook. They are used to execute simple tasks at the command line against one or more managed nodes.
An ad-hoc command consists of two main parts: the inventory of hosts to run the command on, and the Ansible module to execute. Here’s the basic syntax for an ad-hoc command:
ansible [host-pattern] -m [module] -a "[module options]"[host-pattern]can be a single host, a group from the inventory, or a wildcard to affect multiple hosts.-m [module]specifies the module to run. If not given, thecommandmodule is the default.-a "[module options]"provides the arguments or parameters to the module.
Examples of Ad-Hoc Commands
1. Ping all servers to check connectivity:
ansible all -m pingThis uses the ping module, which is not an ICMP ping but rather an Ansible module that tests if you can log into the hosts and it will respond.
2. Check uptime on all servers:
ansible all -a "uptime"This uses the default command module to execute the uptime command.
3. Manage packages:
- Install a package on all Debian servers:
ansible debian -m apt -a "name=git state=present"This uses the apt module to ensure the package git is installed.
- Remove a package from all Red Hat servers:
ansible redhat -m yum -a "name=httpd state=absent"This uses the yum module to ensure the package httpd is removed.
4. Manage files and directories:
- Create a directory on all servers:
ansible all -m file -a "path=/path/to/directory state=directory"This uses the file module to create a directory.
- Remove a file from all servers:
ansible all -m file -a "path=/path/to/file state=absent"5. Manage services:
- Start a service on all servers:
ansible all -m service -a "name=httpd state=started"- Restart a service on all web servers:
ansible webservers -m service -a "name=httpd state=restarted"6. Copy a file to all servers:
ansible all -m copy -a "src=/local/path/to/file dest=/remote/path/to/file"7. Execute a shell command:
ansible all -m shell -a "echo 'Hello, World!' > /path/to/file"The shell module executes the command through the shell, which allows you to use shell operators like > and |.
Using Ad-Hoc Commands for Quick Checks or Fixes
Ad-hoc commands are particularly useful for quick checks or when you need to make an immediate change to a group of servers. For instance, you can quickly restart a service that’s been updated, or clear temporary files from all servers. They’re also useful for system administrators to do quick one-time actions without the overhead of writing a full playbook.
Limitations of Ad-Hoc Commands
While ad-hoc commands are powerful and convenient for simple tasks, they do have limitations:
- They are not reusable like playbooks.
- They are not idempotent by default; running the same command multiple times may have different results.
- Complex tasks and sequencing of tasks are not possible.
- No error handling or conditional execution (except for the built-in behavior of the module being used).
When you find yourself repeatedly using an ad-hoc command, it’s usually a sign that you should write a playbook for that task. Playbooks can be stored in version control, shared among your team, and are the basis for scalable automation and orchestration with Ansible.
Part 3: Your First Playbook
Creating your first Ansible playbook is a significant step in automating your infrastructure. Here is a more detailed walkthrough, including an example.
Understanding Playbooks
Playbooks are the core configuration, deployment, and orchestration language of Ansible. They are expressed in YAML format and describe the tasks to be executed on remote machines, the roles, and more complex workflows like multi-machine deployments.
Basic Structure of a Playbook
A playbook is made up of one or more ‘plays’. A play is a set of tasks that will be run on a group of hosts. Here’s the basic structure:
---
- name: This is a play within a playbook
hosts: target_hosts
become: yes_or_no
vars:
variable1: value1
variable2: value2
tasks:
- name: This is a task
module_name:
module_parameter1: value
module_parameter2: value
- name: Another task
module_name:
module_parameter: value
handlers:
- name: This is a handler
module_name:
module_parameter: value---indicates the start of YAML content.namegives the play or task a name (optional, but recommended).hostsspecifies the hosts group from your inventory.becomeif set toyes, enables user privilege escalation (likesudo).varslist variables and their values.tasksis a list of tasks to execute.handlersare special tasks that run at the end of a play if notified by another task.
Writing Your First Playbook
Let’s say you want to write a playbook to install and start Apache on a group of servers. Here’s a simple example of what that playbook might look like:
---
- name: Install and start Apache
hosts: webservers
become: yes
tasks:
- name: Install Apache
apt:
name: apache2
state: present
update_cache: yes
when: ansible_facts['os_family'] == "Debian"
- name: Ensure Apache is running and enabled to start at boot
service:
name: apache2
state: started
enabled: yesIn this playbook:
- We target a group of hosts named
webservers. - We use the
becomedirective to get administrative privileges. - We have two tasks, one to install Apache using the
aptmodule, which is applicable to Debian/Ubuntu systems, and another to ensure that the Apache service is running and enabled to start at boot using theservicemodule.
Running the Playbook
To run the playbook, you use the ansible-playbook command:
ansible-playbook path/to/your_playbook.ymlAssuming you’ve set up your inventory and the hosts are accessible, Ansible will connect to the hosts in the webservers group and perform the tasks listed in the playbook.
Checking Playbook Syntax
Before you run your playbook, it’s a good idea to check its syntax:
ansible-playbook path/to/your_playbook.yml --syntax-checkDry Run
You can also do a ‘dry run’ to see what changes would be made without actually applying them:
ansible-playbook path/to/your_playbook.yml --checkVerbose Output
If you want more detailed output, you can add the -v, -vv, -vvv, or -vvvv flag for increasing levels of verbosity.
Idempotence
One of Ansible’s key principles is idempotence, meaning you can run the playbook multiple times without changing the result beyond the initial application. Ansible modules are generally idempotent and won’t perform changes if they detect the desired state is already in place.
By creating a playbook, you’ve taken the first step towards infrastructure automation with Ansible. As you become more comfortable, you can start to explore more complex tasks, roles, and even entire workflows, building on the foundation of what you’ve learned here.
Part 4: Variables and Facts in Ansible
In Ansible, variables are essential for creating flexible playbooks and roles that can be reused in different environments. Facts are a special subset of variables that are automatically discovered by Ansible from the systems it is managing.
Variables
Variables in Ansible can be defined in various places:
- Playbooks: Directly inside a playbook to apply to all included tasks and roles.
- Inventory: Within your inventory, either as individual host variables or group variables.
- Role Defaults: Inside a role using the
defaults/main.ymlfile, which defines the lowest priority variables. - Role Vars: Inside a role using the
vars/main.ymlfile, which defines higher priority variables. - Task and Include Parameters: Passed as parameters to tasks or includes.
- On the Command Line: Using the
-eor--extra-varsoption. - Variable Files: Via external files, typically YAML, which can be included using
vars_filesin playbooks or loaded on demand.
Variables can be used to parameterize playbook and role content. They use the Jinja2 templating system and are referenced using double curly braces {{ variable_name }}.
Examples of Defining Variables
In a playbook:
---
- hosts: all
vars:
http_port: 80
max_clients: 200
tasks:
- name: Open HTTP port in the firewall
firewalld:
port: "{{ http_port }}/tcp"
permanent: true
state: enabledIn an inventory file:
[webservers]
web1.example.com http_port=80 max_clients=200
web2.example.com http_port=8080 max_clients=100In a variables file:
vars/httpd_vars.yml:
---
http_port: 80
max_clients: 200In a playbook using vars_files:
---
- hosts: all
vars_files:
- vars/httpd_vars.yml
tasks:
- name: Start httpd
service:
name: httpd
state: startedFacts
Facts are system properties collected by Ansible from hosts when running playbooks. Facts include things like network interface information, operating system, IP addresses, memory, CPU, and disk information, etc.
You can access them in the same way as variables:
---
- hosts: all
tasks:
- name: Display the default IPv4 address
debug:
msg: "The default IPv4 address is {{ ansible_default_ipv4.address }}"Gathering Facts
By default, Ansible gathers facts at the beginning of each play. However, you can disable this with gather_facts: no if you don’t need them or want to speed up your playbook execution. You can also manually gather facts using the setup module:
---
- hosts: all
gather_facts: no
tasks:
- name: Manually gather facts
setup:
- name: Use a fact
debug:
msg: "The machine's architecture is {{ ansible_architecture }}"Using Fact Variables in Templates
Facts can be very useful when used in templates to dynamically generate configuration files. For example:
templates/sshd_config.j2:
Port {{ ansible_ssh_port | default('22') }}
ListenAddress {{ ansible_default_ipv4.address }}
PermitRootLogin {{ ssh_root_login | default('yes') }}Then, using the template in a task:
---
- hosts: all
vars:
ssh_root_login: 'no'
tasks:
- name: Configure sshd
template:
src: templates/sshd_config.j2
dest: /etc/ssh/sshd_configHere, we’re using a combination of facts (ansible_default_ipv4.address, ansible_ssh_port) and a variable (ssh_root_login) to populate the sshd_config file.
Remember, the flexibility and power of Ansible often come from effectively using variables and facts to write dynamic playbooks that adapt to the target environment’s state and the input variables.
Part 5: Templates and Jinja2
Ansible uses Jinja2 templating to enable dynamic expressions and access to variables.
Example of a Template
If you want to configure an Apache virtual host, you could create a template for the configuration file (vhost.conf.j2):
<VirtualHost *:{{ http_port }}>
ServerName {{ ansible_hostname }}
DocumentRoot /var/www/html
<Directory /var/www/html>
Options Indexes FollowSymLinks
AllowOverride All
Require all granted
</Directory>
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>And then use the template in a task:
tasks:
- name: Configure Apache VHost
template:
src: vhost.conf.j2
dest: /etc/apache2/sites-available/001-my-vhost.conf
notify: restart apachePart 6: Handlers
Handlers are special tasks that run at the end of a play if notified by another task.
Using Handlers
Here is how you define and use a handler to restart Apache when its configuration changes:
handlers:
- name: restart apache
service:
name: apache2
state: restarted
tasks:
- name: Configure Apache VHost
template:
src: vhost.conf.j2
dest: /etc/apache2/sites-available/001-my-vhost.conf
notify: restart apacheThe notify directive in the task tells Ansible to run the “restart apache” handler if the task results in changes.
Part 7: Roles
Certainly! Roles are one of the most powerful features in Ansible for creating reusable and modular content. Let’s take a detailed look at roles with an example.
Understanding Roles
Roles in Ansible are a way to group together various aspects of your automation – tasks, variables, files, templates, and more – into a known file structure. Using roles can help you organize your playbooks better, make them more maintainable, and also share or reuse them.
Anatomy of a Role
A role typically includes the following components:
tasks: The main list of tasks that the role executes.handlers: Handlers, which may be used within or outside this role.defaults: Default variables for the role.vars: Other variables for the role that are more likely to be changed.files: Contains files which can be deployed via this role.templates: Contains templates which can be deployed via this role.meta: Defines some metadata for the role, including dependencies.
Here’s how the directory structure of a typical role named my_role might look:
my_role/
├── defaults/
│ └── main.yml
├── handlers/
│ └── main.yml
├── meta/
│ └── main.yml
├── tasks/
│ └── main.yml
├── templates/
│ └── my_template.j2
├── files/
│ └── my_file.txt
└── vars/
└── main.ymlCreating a Role
To create a role, you can use the ansible-galaxy command line tool, which will create the directory structure for you:
ansible-galaxy init my_roleExample Role
Let’s say you have a role that’s responsible for installing and configuring Nginx on a Linux system. The role might look something like this:
tasks/main.yml
---
# tasks file for roles/nginx
- name: Install nginx
apt:
name: nginx
state: present
notify:
- restart nginx
- name: Upload nginx configuration file
template:
src: nginx.conf.j2
dest: /etc/nginx/nginx.conf
notify:
- restart nginxhandlers/main.yml
---
# handlers file for roles/nginx
- name: restart nginx
service:
name: nginx
state: restartedtemplates/nginx.conf.j2
user www-data;
worker_processes auto;
pid /run/nginx.pid;
events {
worker_connections {{ nginx_worker_connections }};
}
http {
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout {{ nginx_keepalive_timeout }};
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
# Other configuration...
}defaults/main.yml
---
# defaults file for roles/nginx
nginx_worker_connections: 1024
nginx_keepalive_timeout: 65meta/main.yml
---
# meta file for roles/nginx
dependencies: []Using the Role in a Playbook
Once you have your role defined, you can use it in a playbook like this:
---
- hosts: web_servers
become: yes
roles:
- my_roleThe playbook will apply the my_role role to all hosts in the web_servers group.
By using roles, you can keep your playbook simple and legible, while encapsulating the complexity in your roles. Each role is self-contained, making them easy to reuse across different projects.
Remember, roles can be as simple or complex as needed, they can include variables that you might want to prompt for, they can have dependencies on other roles, and they can be tested in isolation or as part of a playbook. They are a key feature to mastering Ansible for configuration management and application deployment at scale.
Alright, let’s delve into some advanced concepts of Ansible. These are typically used in larger or more dynamic environments and can help streamline complex automation workflows.
Part 8: Dynamic Inventory
In static inventories, the list of hosts is fixed and defined manually. In dynamic environments, like cloud infrastructure, where new instances can be created and destroyed at any time, a dynamic inventory is essential.
Dynamic Inventory Script
Ansible can use an inventory script (or plugin) to generate inventory dynamically from external data sources. For example, if you’re using AWS, Ansible can query the current instances to build its inventory.
Here’s how you can use a dynamic inventory script:
- Obtain or write a dynamic inventory script that pulls data from your resource manager (e.g., AWS, GCP, Azure).
- Make sure the script outputs JSON formatted for Ansible.
- Reference the script in your Ansible commands:
ansible -i path/to/dynamic_inventory.py all -m pingExample of Using an AWS Dynamic Inventory
If you have aws_ec2 plugin enabled, you can define a yaml file with the necessary configurations:
plugin: aws_ec2
regions:
- us-east-1
keyed_groups:
- key: tags
prefix: tagThen, you can reference this file in your Ansible commands:
ansible-inventory -i my_aws_ec2.yaml --graph
Part 9: Understanding Ansible Vault
Ansible Vault is a tool within Ansible for encrypting sensitive data. This feature is essential for managing confidential information such as passwords or keys without exposing them in plain text in your playbooks or roles.
Key Features
- Encrypting Files: Encrypt any Ansible structured data file to securely manage sensitive data.
- Editing Encrypted Files: Ansible Vault allows for easy editing of encrypted files.
- Decryption for Viewing/Editing: Encrypted files can be decrypted for editing but should be done cautiously.
- Seamless Playbook Integration: Encrypted files can be used like normal files in playbooks, with decryption handled automatically during playbook execution.
Creating and Managing Encrypted Files
- Creating an Encrypted File:
ansible-vault create secret.ymlEnter a password when prompted. This file can now store sensitive information.
- Editing an Encrypted File:
ansible-vault edit secret.ymlYou will need to provide the encryption password.
- Encrypting an Existing File:
ansible-vault encrypt somefile.yml- Decrypting a File:
ansible-vault decrypt secret.ymlBe cautious as this removes the encryption.
Example Usage in a Playbook
Suppose you have a playbook site.yml and an encrypted variable file vars.yml (encrypted using Ansible Vault) with the following content:
# vars.yml
username: admin
password: supersecretPlaybook (site.yml):
- hosts: all
vars_files:
- vars.yml
tasks:
- name: Print username
debug:
msg: "The username is {{ username }}"In this playbook, vars.yml is referenced in the vars_files section. When running this playbook, Ansible requires the vault password to decrypt vars.yml:
ansible-playbook site.yml --ask-vault-passYou will be prompted for the vault password that was used to encrypt vars.yml. Once provided, Ansible decrypts the file and uses the variables within the playbook.
Best Practices
- Secure Password Storage: Keep your Ansible Vault password in a secure location and never store it in version control.
- Selective Encryption: Encrypt only the sensitive parts of your data, keeping other data in unencrypted files for easier maintenance.
- Version Control Safety: Encrypted files can safely be committed to version control without revealing sensitive data.
By using Ansible Vault, you can securely manage sensitive data in your automation scripts, ensuring that confidential information is not exposed in your repositories or logs.
Part 10: Custom Modules
Sometimes, you might need functionality that’s not available in the Ansible built-in modules. In such cases, you can write your own custom modules.
Creating a Custom Module
Custom modules can be written in any language that can return JSON, but Python is the most common choice. Here’s a simple example of a custom module written in Python:
#!/usr/bin/python
from ansible.module_utils.basic import AnsibleModule
def main():
module = AnsibleModule(
argument_spec=dict(
message=dict(required=True, type='str')
)
)
message = module.params['message']
result = dict(
msg="Hello, {}!".format(message),
changed=False
)
module.exit_json(**result)
if __name__ == '__main__':
main()You can store this module in a directory and reference it with the library parameter in your ansible.cfg or by directly invoking it in a playbook.
Part 10: Playbook Optimization
As playbooks grow in complexity, it’s essential to optimize them for performance and maintainability.
Asynchronous Actions
You can run tasks asynchronously if they’re likely to take a long time to complete, using the async keyword:
- name: Run a long-running process
command: /usr/bin/long_running_operation --do-stuff
async: 3600
poll: 0In this example, Ansible starts the task and immediately moves on to the next task without waiting for completion.
Error Handling
To handle errors in your playbooks, you can use blocks:
- name: Handle errors
block:
- name: Attempt to do something
command: /bin/false
register: result
ignore_errors: true
- name: Do something if the above task failed
command: /bin/something_else
when: result is failed
rescue:
- name: Do this if there was an error in the block
debug:
msg: "There was an error"Using include and import
To keep playbooks clean and manageable, you can use include and import statements to separate tasks, handlers, and even variables into different files:
- name: Include tasks from another file
include_tasks: tasks/other_tasks.ymlPart 11: Testing and Troubleshooting
It’s important to test playbooks and roles to ensure they work as intended.
Testing with ansible-playbook Flags
--syntax-checkhelps with finding syntax errors in a playbook.-Cor--checkruns a playbook in a “dry run” mode, making no changes.-vvvenables verbose mode to help with debugging.
Debugging
The debug module is a useful tool for printing variables and expressions to the output for debugging purposes:
- name: Print the value of 'my_variable'
debug:
var: my_variablePart 12: Best Practices
As you advance your use of Ansible, keep in mind some best practices:
- Keep your playbooks simple and readable.
- Use roles to organize tasks.
- Store secrets in Ansible Vault.
- Write idempotent tasks.
- Use version control for your playbooks and roles.