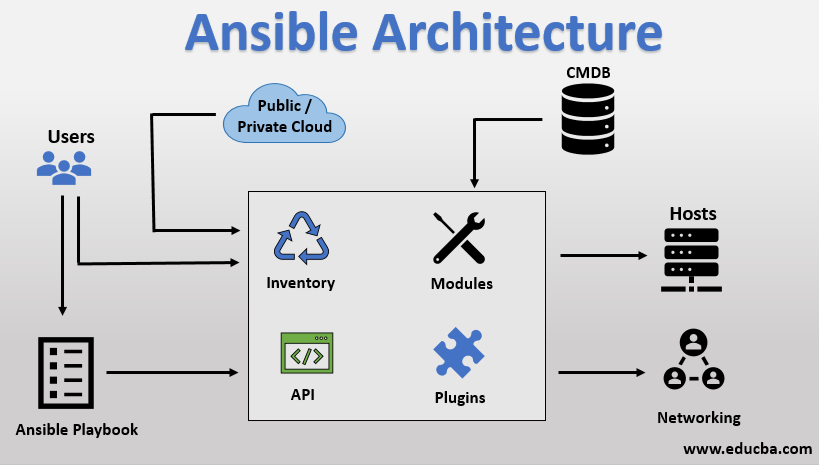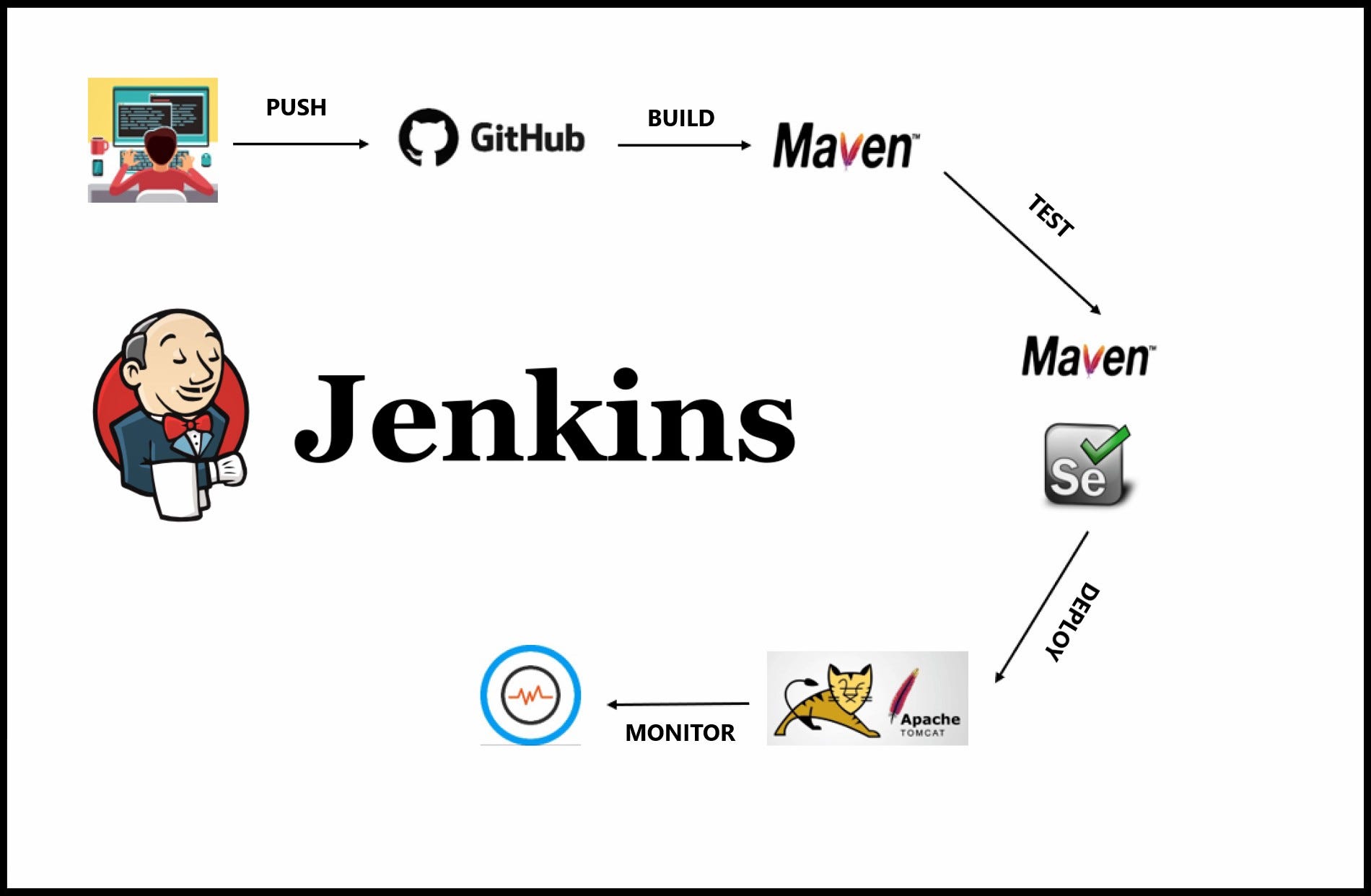
Introduction to Jenkins
Overview of CI/CD
Definition and Importance:
- Continuous Integration (CI) and Continuous Delivery (CD) are foundational practices in modern software development that aim to improve software delivery speed and quality.
- CI is the practice of automating the integration of code changes from multiple contributors into a single software project. It involves automated testing to detect integration errors as quickly as possible.
- CD extends CI by automating the delivery of applications to selected infrastructure environments. It ensures that the software can be reliably released at any time.
Continuous Integration vs. Continuous Delivery vs. Continuous Deployment:
- Continuous Integration: Developers frequently merge their code changes into a central repository, after which automated builds and tests are run.
- Continuous Delivery: This is an extension of CI, where the software release process is automated. This ensures that the software can be released to production at any time with the push of a button.
- Continuous Deployment: A step beyond Continuous Delivery. Every change that passes all stages of the production pipeline is released to customers. There’s no human intervention, and only a failed test will prevent a new change to be deployed to production.
Introduction to Jenkins
History and Evolution:
- Jenkins was originally developed as the Hudson project in 2004 by Kohsuke Kawaguchi, a Sun Microsystems employee.
- It was renamed Jenkins in 2011 after a dispute with Oracle, which had acquired Sun Microsystems.
- Jenkins has evolved to become one of the most popular automation servers, with a strong community and a vast plugin ecosystem.
Jenkins in the DevOps Culture:
- Jenkins plays a pivotal role in DevOps by providing a robust platform for automating the various stages of the DevOps pipeline.
- It bridges the gap between software development and IT operations, enabling faster and more efficient delivery of software.
Key Features and Benefits:
- Extensibility: Jenkins can be extended via its vast plugin ecosystem, making it adaptable to almost any tool or technology in the CI/CD pipeline.
- Flexibility: It supports various SCM tools like Git, SVN, and Mercurial and can integrate with numerous testing and deployment technologies.
- Ease of Use: Jenkins is relatively easy to set up and configure, and it offers a user-friendly web interface for managing the CI/CD process.
- Distributed Nature: Jenkins can distribute work across multiple machines for faster builds, tests, and deployments.
- Rich Community: Being open-source, Jenkins has a large and active community, providing a wealth of plugins and shared knowledge.
Examples:
- A typical Jenkins CI pipeline includes pulling code from a Git repository, building the code using a tool like Maven or Gradle, running tests, and then packaging the application for deployment.
- In a CD setup, Jenkins could further automate the deployment of the built application to a staging server, run additional tests, and prepare it for production deployment.
Setting Up Jenkins
Installation and Configuration
System Requirements:
- Java: Jenkins requires Java (JRE or JDK) to run. The recommended version is Java 11, but it also supports Java 8.
- Memory: Minimum of 256 MB of heap space and 1 GB of RAM.
- Disk Space: At least 10 GB of disk space for Jenkins and additional space for builds and jobs.
- Web Browser: A modern web browser for accessing the Jenkins web interface.
Installing Jenkins on Various Platforms:
- Windows:
- Download the Jenkins Windows installer from the Jenkins website.
- Run the installer and follow the on-screen instructions.
- Jenkins will be installed as a Windows service.
- Linux:
- Jenkins can be installed on Linux using package managers like
apt(for Ubuntu/Debian) oryum(for Red Hat/CentOS). - Example for Ubuntu:
bash wget -q -O - https://pkg.jenkins.io/debian/jenkins.io.key | sudo apt-key add - sudo sh -c 'echo deb http://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list' sudo apt-get update sudo apt-get install jenkins - Jenkins will start as a daemon on Linux.
- macOS:
- The easiest way is to use Homebrew:
bash brew install jenkins-lts - Start Jenkins using:
bash brew services start jenkins-lts
Initial Setup and Configuration:
- After installation, open your browser and go to
http://localhost:8080. - The first time you access Jenkins, it will ask for an initial admin password, which can be found in a file specified in the console output.
- After entering the password, you’ll be prompted to install suggested plugins or select specific plugins.
- Create an admin user and configure the Jenkins instance.
Jenkins Dashboard
Navigating the Interface:
- The Jenkins dashboard is the central point for managing Jenkins.
- It displays a summary of Jenkins jobs, including the status of recent builds.
- The left-hand side menu provides options for managing Jenkins, including creating new jobs, managing users, and system configuration.
Basic Configuration Options:
- Manage Jenkins: This section allows you to configure system settings, manage plugins, and set up global security.
- Creating Jobs: From the dashboard, you can create new Jenkins jobs by selecting “New Item.”
- System Configuration: Here, you can configure system-level settings like JDK installations, Maven configurations, and environment variables.
- Security Configuration: In “Configure Global Security,” you can set up authentication methods, authorize users, and configure security realms.
Examples:
- Creating a Freestyle Job:
- Go to the Jenkins dashboard.
- Click on “New Item.”
- Enter a name for the job, select “Freestyle project,” and click OK.
- Configure the job by specifying source code management, build triggers, and build steps.
- Save the job and run it to see the results.
- Setting Up a Maven Project:
- From the dashboard, create a new item and select “Maven project.”
- Provide the details of your Maven project, including repository URL and build goals.
- Jenkins will build the Maven project based on the provided POM file and goals.
Jenkins Jobs and Builds
Creating Jobs
Job Types in Jenkins:
- Freestyle Project: The most flexible and easy-to-use type. Suitable for most use cases.
- Maven Project: Optimized for projects built with Apache Maven. It uses information from the POM file.
- Pipeline: For complex pipelines (as code), typically using a
Jenkinsfile. Allows for implementing sophisticated CI/CD workflows. - Multibranch Pipeline: Automatically creates a pipeline for each branch in your source control.
- External Job: Monitor executions run outside of Jenkins.
Configuring Source Code Management (Git, SVN):
- Jenkins can integrate with various SCM tools like Git, Subversion (SVN), Mercurial, etc.
- Git Example:
- In the job configuration, select “Git” in the Source Code Management section.
- Enter the Repository URL (e.g.,
https://github.com/user/repo.git). - Add credentials if the repository is private.
- Optionally specify branches to build.
- SVN Example:
- Select “Subversion” in the Source Code Management section.
- Enter the Repository URL (e.g.,
http://svn.example.com/project). - Configure credentials and additional options as needed.
Build Triggers and Scheduling:
- Trigger Types:
- Poll SCM: Checks the SCM for changes at specified intervals.
- Build after other projects are built: Triggers a build after the completion of a specified project.
- Build periodically: Schedule at specific intervals (e.g.,
H/15 * * * *for every 15 minutes). - GitHub hook trigger for GITScm polling: Triggers a build when a change is pushed to GitHub (requires webhook configuration in GitHub).
- Example: To build every night at 2 AM, use
0 2 * * *in “Build periodically.”
Build Process
Understanding Build Steps:
- Build steps are actions to execute during the build process.
- Common steps include executing shell scripts or batch commands, invoking build tools like Maven or Gradle, running tests, etc.
- Example: A simple shell script step could be
echo "Building project"for a Linux-based system or a batch command likeecho Building projecton Windows.
Build Environment Configuration:
- In the job configuration, you can set various environment options like:
- Delete workspace before build starts: To ensure a clean environment for each build.
- Use secret text(s) or file(s): For handling credentials.
- Set environment variables: To define or override environment variables for the build.
Post-build Actions:
- Actions to perform after a build is completed.
- Common actions include:
- Archiving artifacts: Save build outputs for later use.
- Publishing JUnit test results: Process and display test results.
- Sending email notifications: Notify team members of build results.
- Deploying to a server: Automatically deploy successful builds.
- Example: To archive all
jarfiles produced in a build, use**/*.jarin “Archive the artifacts.”
Jenkins Pipeline
Pipeline as Code
Concept:
- Pipeline as Code refers to defining the deployment pipeline through code, rather than manual job creation in Jenkins.
- This is typically done using a
Jenkinsfile, which is a text file that contains the definition of a Jenkins Pipeline and is checked into source control.
Advantages:
- Version Control: Pipelines can be versioned and reviewed like any other code.
- Reusability: Pipelines can be shared across different projects.
- Consistency: Ensures consistency in the build process across environments.
Example of a Jenkinsfile:
pipeline {
agent any
stages {
stage('Build') {
steps {
echo 'Building..'
// Add build steps here
}
}
stage('Test') {
steps {
echo 'Testing..'
// Add test steps here
}
}
stage('Deploy') {
steps {
echo 'Deploying..'
// Add deployment steps here
}
}
}
}Creating and Managing Pipelines
Creating a Pipeline:
- Using a Jenkinsfile:
- Create a
Jenkinsfilein your SCM repository. - In Jenkins, create a new item and select “Pipeline.”
- In the Pipeline section, specify the SCM and the path to the
Jenkinsfile.
- Directly in Jenkins:
- Create a new Pipeline item in Jenkins.
- Directly write or paste the pipeline script in the Pipeline section.
Managing Pipelines:
- Pipelines are managed in Jenkins just like any other job.
- They can be triggered manually, by SCM commits, or on a schedule.
- Jenkins provides visualization of pipeline stages and progress.
Scripted vs. Declarative Pipelines
Scripted Pipeline:
- Definition: Uses a more traditional Groovy syntax. Offers more flexibility and control.
- Syntax: Written in Groovy-based DSL.
- Control Structures: Allows complex logic, loops, and conditionals.
- Example:
node {
stage('Build') {
echo 'Building..'
// Build steps
}
stage('Test') {
echo 'Testing..'
// Test steps
}
stage('Deploy') {
echo 'Deploying..'
// Deploy steps
}
}Declarative Pipeline:
- Definition: Introduced for a simpler and more opinionated syntax for authoring Jenkins Pipeline.
- Syntax: More straightforward and easier to read.
- Structure: Has a predefined structure and sections.
- Example: (Same as the example provided in the Pipeline as Code section).
Key Differences:
- Flexibility: Scripted pipelines offer more flexibility and control but are more complex.
- Ease of Use: Declarative pipelines are easier to write and understand, especially for beginners.
- Syntax: Scripted pipelines use a Groovy-based DSL, while Declarative pipelines have a more structured and pre-defined format.
Managing Plugins in Jenkins
Finding and Installing Plugins
Finding Plugins:
- Jenkins Plugin Manager: The primary method to find plugins is through the Jenkins Plugin Manager in the Jenkins web interface.
- Jenkins Plugin Site: The Jenkins Plugin Site is also a valuable resource for exploring available plugins, where you can search and read documentation.
Installing Plugins:
- Via Jenkins Web Interface:
- Navigate to Manage Jenkins > Manage Plugins.
- Switch to the Available tab to browse or search for plugins.
- Select the desired plugin(s) and click Install without restart or Download now and install after restart.
- Jenkins will download and install the plugin(s).
- Manual Installation:
- If a plugin is not available in the Plugin Manager, it can be manually downloaded from the Jenkins Plugin Site and uploaded.
- Navigate to Manage Jenkins > Manage Plugins > Advanced tab.
- Under Upload Plugin, choose the
.hpifile and click Upload.
Example:
- Installing the Git Plugin:
- Go to Manage Plugins.
- In the Available tab, search for “Git plugin.”
- Select it and click Install without restart.
- Jenkins will install the plugin and may require a restart.
Plugin Configuration and Management
Configuring Plugins:
- After installation, many plugins require configuration.
- Configuration can typically be done through Manage Jenkins > Configure System or a specific section in the Jenkins dashboard.
- For example, the Git plugin requires setting up Git installations and global configurations.
Managing Existing Plugins:
- Updating Plugins:
- Regularly update plugins for new features and security fixes.
- Go to Manage Plugins > Updates tab to see available updates.
- Disabling/Enabling Plugins:
- Plugins can be disabled without uninstalling them.
- Navigate to Manage Plugins > Installed tab, and use the Enable/Disable button as needed.
- Uninstalling Plugins:
- If a plugin is no longer needed, it can be uninstalled.
- In the Installed tab, select the plugin and click Uninstall.
Example:
- Configuring the Mailer Plugin:
- After installing the Mailer plugin, go to Manage Jenkins > Configure System.
- Scroll to the E-mail Notification section.
- Enter your SMTP server details and email address.
- Save the configuration.
Distributed Builds in Jenkins
Master-Slave Architecture
Concept:
- Jenkins uses a Master-Slave architecture to manage distributed builds.
- The Master is the main Jenkins server, responsible for scheduling builds, dispatching jobs to nodes (slaves), and monitoring them.
- Slaves (or Nodes) are servers where the actual job execution takes place.
Advantages:
- Scalability: Distributes workload across multiple machines, improving build times.
- Flexibility: Different jobs can be run in different environments.
- Resource Optimization: Utilizes various hardware and software configurations as needed.
Reference:
Configuring and Managing Nodes
Setting Up a Slave Node:
- Adding a Node:
- In Jenkins, navigate to Manage Jenkins > Manage Nodes and Clouds.
- Click on New Node, enter a name, select Permanent Agent, and click OK.
- Configure the node details (remote root directory, labels, usage, launch method, etc.).
- Launch Methods:
- SSH: Connects to the slave via SSH. Requires Java on the slave machine.
- JNLP (Java Web Start): The slave connects to the master using a JNLP agent.
- Windows agents: Can be connected using Windows-specific methods like DCOM.
Managing Nodes:
- Monitoring: The master provides a monitoring view for all nodes, showing their status and workload.
- Configuring Executors: Executors are individual build slots on a node. The number of executors can be configured based on the node’s capacity.
- Maintaining Nodes: Nodes can be temporarily taken offline for maintenance or permanently removed.
Example:
- Configuring a Linux Node via SSH:
- Add a new node as described above.
- In the Launch method, select Launch agents via SSH.
- Enter the host IP, credentials, and other SSH settings.
- Save and Jenkins will try to establish a connection to the node.
Reference:
Jenkins Security
Access Control
User Authentication and Authorization:
- Objective: Ensure that only authorized users can access Jenkins and perform specific tasks.
- Process:
- Jenkins supports various authentication methods like LDAP, Active Directory, and internal Jenkins user database.
- Authorization strategies define what authenticated users are allowed to do. Common strategies include Matrix-based security and Project-based Matrix Authorization.
- Example:
- Configuring LDAP authentication:
- Navigate to Manage Jenkins > Configure Global Security.
- Select LDAP in the Security Realm section and enter LDAP server details.
Role-Based Access Control (RBAC)
Concept:
- RBAC in Jenkins allows fine-grained access control based on roles assigned to users or groups.
- Roles can be defined globally or per project, with specific permissions.
Implementation:
- Install the Role-based Authorization Strategy plugin.
- Define roles in Manage and Assign Roles under Manage Jenkins.
- Assign roles to users or groups with specific permissions.
Reference:
Securing Jenkins
Best Practices for Jenkins Security:
- Regular Updates: Keep Jenkins and its plugins updated to the latest versions.
- Secure Configuration: Follow the principle of least privilege. Limit permissions and access to what is necessary.
- Use HTTPS: Configure Jenkins to use HTTPS for secure communication.
- Audit Logs: Enable and monitor audit logs to track changes and actions in Jenkins.
- Firewall Configuration: Restrict access to Jenkins servers using firewalls.
Managing Credentials:
- Objective: Securely store and manage credentials used in Jenkins jobs.
- Process:
- Use the Credentials Plugin to store credentials securely in Jenkins.
- Credentials can be scoped globally or to specific Jenkins items.
- Supports various credential types like username/password, SSH keys, and secret text.
- Example:
- Adding SSH credentials:
- Navigate to Credentials > System > Global credentials > Add Credentials.
- Select SSH Username with private key and enter the required details.
- Reference:
- Credentials Plugin – Jenkins