What is the difference between a hard link and a soft link in Linux?
- Hard Link: Creates another reference to the same inode as the original file. If you delete the original, the hard link will still access the file’s contents. For example,
ln original.txt hardlink.txtcreates a hard link. - Soft Link (Symbolic Link): Points to the file name rather than the inode. If the original file is deleted, the link becomes broken. For example,
ln -s original.txt symlink.txtcreates a symbolic link.
How can you check the memory usage of a Linux system?
- Use
free -mto display memory usage in megabytes, including total, used, free, and swap memory. Example:
$ free -m
total used free shared buffers cached
Mem: 16034 12453 3580 114 153 9512
-/+ buffers/cache: 2787 13246
Swap: 2047 60 1987How do you find the IP address of a Linux system?
hostname -Iorip addr showcan be used to find the IP addresses associated with all network interfaces. Example:
$ hostname -I
192.168.1.4 10.0.0.1What is the purpose of the “chmod” command in Linux?
chmodchanges the permissions of a file or directory. For example,chmod 755 myfilesets the permissions to read, write, and execute for the owner, and read and execute for the group and others.
What is the purpose of the “grep” command?
grepsearches files for lines that match a pattern and then returns the lines. Example:grep "error" logfile.txtwill search for the word “error” inlogfile.txt.
How do you change the password for a user in Linux?
passwd [username]allows you to change the password for a user. If run by the superuser, it can change the password for any user. Example:sudo passwd johnresets John’s password.
What is the purpose of the “crontab” in Linux?
crontabis used to schedule periodic tasks. Entries in a crontab file dictate what commands to run and when to run them. Example:
0 23 * * * /usr/bin/find / -name core > /tmp/corefiles.txtHow do you schedule a cron job in Linux?
- Use
crontab -eto open the cron table for editing and add lines in the formatminute hour day month day-of-week command. Example:
30 04 * * 1 tar -zcf /var/backups/home.tgz /home/How would you address a disk space full issue in Linux?
- Use
df -hto check for full filesystems, anddu -sh /path/to/directoryto find out space usage by directory. Clear space by removing unnecessary files or archiving old logs. Example:
$ df -h
$ du -sh /var/logWhat steps would you take when running out of memory in Linux?
- Identify memory-intensive processes using
toporhtopand kill unnecessary processes or increase swap space. Example:
$ topHow do you troubleshoot high CPU usage on a Linux server?
- Use
toporhtopto find which processes are using the most CPU and investigate whether these processes can be optimized or need more resources. Example:
$ htopCan you describe the boot process of a Linux system?
- The Linux boot process includes:
- BIOS/UEFI: Initializes hardware and finds the boot device.
- Bootloader (GRUB): Loads the kernel.
- Kernel: Initializes devices and kernel subsystems, mounts the root filesystem.
- Init: Starts processes defined in
init.rcincluding system services. - Runlevel/scripts: Executes scripts to finalize system initialization.
You need to transfer a large file securely between two Linux servers. What tools or protocols would you use, and why?
- Use
scporrsyncover SSH for secure data transfer, as they encrypt the data in transit. Example:
$ scp largefile.tar.gz user@192.168.1.5:/path/to/destination/A user accidentally deleted an important file, and you need to recover it from the backup. What are the steps to restore the file?
- Locate the backup file, verify its integrity, and copy it back to the original location using
cporrsync. Ensure the file permissions and ownership are restored correctly. Example:
$ rsync -avz backupfile.tar.gz /path/to/restore/A user reports that they are unable to connect to a remote Linux server using SSH. How would you troubleshoot this connectivity issue?
- Check if SSH is running on the server (
systemctl status sshd), verify network connectivity (ping), check firewall rules, and look at the SSH configuration for any restrictions. Example:
$ systemctl status sshd
$ ping server_ipHow would you find all files larger than 100MB in the /home directory and its subdirectories?
- Use the
findcommand:find /home -type f -size +100M -exec ls -lh {} \;. This command lists files over 100MB in size along with their detailed information.
What is an inode in Linux?
- An inode is a data structure used to store information about a file or a directory, such as its size, owner, permissions, and pointers to disk blocks.
What does the booting process in Linux involve?
- The booting process is similar to the detailed steps given earlier, involving hardware initialization, bootloader actions, kernel loading, and system service startup through init or systemd scripts.
How do you clear server space if you continuously get a ‘Space not available’ message?
- Regularly clean temporary files, compress or delete old logs, uninstall unused software, and clean up old kernel images. Using commands like
duanddfcan help pinpoint high-usage areas.
What are some of the Linux commands you use daily?
- Common commands include
ls,cd,pwd,cp,mv,mkdir,rm,chmod,chown,top,ps,grep,find,df, anddu.
What are the types of file permissions in Linux?
- File permissions include read (r), write (w), and execute (x), which can be set for the owner, group, and others (world).
How do you resolve continuous ‘Space not available’ issues on a server?
- Regular maintenance tasks should be implemented, such as archiving old files, cleaning up temporary directories, and increasing disk capacity if needed. Commands like
du -h --max-depth=1 / | sort -hrcan help identify where space is being used the most.
What is Swap Space?
Swap space in Linux is used when the amount of physical memory (RAM) is full. If the system needs more memory resources and the RAM is full, inactive pages in memory are moved to the swap space. For example, if your system has 8 GB of RAM and it’s all used up, swap space can help by providing additional space on the hard drive, acting as “virtual memory.”
How do you mount and unmount filesystems in Linux?
To mount a filesystem, you use the mount command, specifying the device and the directory where it should be mounted. For example:
sudo mount /dev/sda1 /mnt/dataTo unmount it, you use the umount command:
sudo umount /mnt/dataHow do you troubleshoot network connectivity issues in Linux?
You can start by checking the physical network connection, then use commands like ping to check connectivity to external IPs, traceroute to trace the path data takes to reach an external server, and ifconfig or ip a to ensure network interfaces are properly configured.
How do you list all the processes running in Linux?
Use the ps aux command to list all running processes with detailed information about each process.
How do you find the process ID (PID) of a running process?
Use the pidof command followed by the process name. For example:
pidof nginxHow do you format a disk in Linux?
To format a disk, you would typically use the mkfs tool, specifying the type of filesystem you want to create. For example:
sudo mkfs.ext4 /dev/sda1What is the difference between a process and a thread?
A process is an instance of a program running in a system, which contains the program code and its activity. Depending on the operating system (OS), a process may contain multiple threads that execute instructions concurrently within the process context.
What is the ulimit command, and how do you use it?
ulimit is used to get and set user limits for system resources, such as file size, memory, or number of open files. For example, to set the maximum number of open files to 1024, you can use:
ulimit -n 1024What is RAID in Linux?
RAID (Redundant Array of Independent Disks) is a way of storing the same data in different places on multiple hard disks to protect data in the case of a drive failure. Linux supports multiple RAID levels like RAID 0, RAID 1, RAID 5, and more.
What is the /proc file system?
The /proc file system is a virtual filesystem in Linux that provides a mechanism for the kernel to send information to processes. It contains a wealth of information about the system hardware and running processes.
How do you secure a Linux server?
Securing a Linux server involves setting up firewalls (e.g., using iptables), securing SSH access (e.g., disabling root login and using key-based authentication), updating software regularly, and using tools like SELinux or AppArmor for mandatory access control.
What is strace command?
strace is a diagnostic, debugging, and instructional utility for monitoring the system calls used by a program and the signals it receives. This command can be very useful for debugging issues with applications.
How do you optimize Linux system performance?
Optimizing Linux performance can involve several strategies, including configuring swappiness, analyzing and limiting CPU usage with tools like nice, renice, or cpulimit, and using performance profiling tools such as perf and sysstat.
What do you understand about process scheduling in Linux?
Process scheduling in Linux is the method by which the kernel allocates CPU time to various processes. The Linux scheduler uses different algorithms (like Completely Fair Scheduler – CFS) to provide efficient and fair resource distribution among the processes.
What is the iptables command, and how to use it for network filtering?
iptables is a user-space utility program that allows a system administrator to configure the IP packet filter rules of the Linux kernel firewall. For example, to block all incoming traffic from a specific IP address:
sudo iptables -A INPUT -s 192.168.1.100 -j DROPHow do you troubleshoot a Linux OS that fails to boot?
Troubleshooting a Linux OS that fails to boot can involve checking the GRUB bootloader for issues, using recovery mode to access logs, examining /var/log/syslog or /var/log/boot.log, and checking hardware compatibility and connections.
What is the init process in Linux?
The init process is the first process started by the Linux kernel and has a process ID (PID) of 1. It is responsible for starting all other processes on the system.
What is SMTP?
SMTP (Simple Mail Transfer Protocol) is a protocol used for sending emails across the Internet. It operates on TCP/IP port 25, and most email systems use SMTP for sending messages between servers.
What is LVM in Linux?
LVM (Logical Volume Manager) in Linux is a device mapper that provides logical volume management for the Linux kernel. It allows for the flexible allocation of disk space, resizing of volumes, and the creation of snapshots.
What is the difference between UDP and TCP?
TCP (Transmission Control Protocol) is a connection-oriented protocol that ensures the complete and correct delivery of data. UDP (User Datagram Protocol) is connectionless, does not guarantee delivery, and is used where quick delivery is preferred over accuracy.
What is /etc/resolv.conf file?
The /etc/resolv.conf file is used to configure DNS (Domain Name System) clients on the system. It specifies nameservers and search domains.
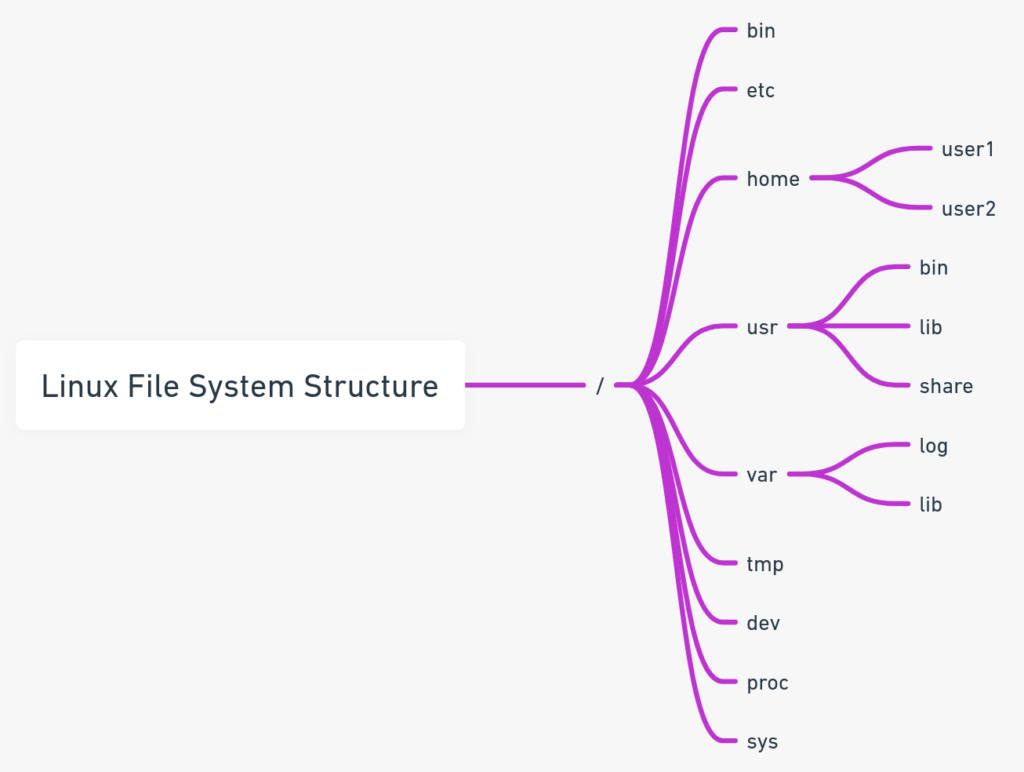
What is the difference between absolute and relative paths in Linux?
An absolute path specifies a location from the root of the filesystem, starting with a /, e.g., /home/user/docs. A relative path starts from the current directory, not the root, e.g., ./docs (meaning the docs directory inside the current directory).
How do you check the status of a service or daemon in Linux?
You can use the systemctl status command followed by the service name. For example:
sudo systemctl status nginxWhat is the difference between /etc/passwd and /etc/shadow files?
The /etc/passwd file stores user account information, which is needed during login. It is readable by all users. The /etc/shadow file stores secure user account information including encrypted passwords and is only accessible by the superuser.
How do you compress and decompress files in Linux?
To compress files, you can use commands like gzip, bzip2, or tar. For example:
tar -czvf archive.tar.gz /path/to/directoryTo decompress:
tar -xzvf archive.tar.gzWhat is the difference between a process and a daemon in Linux?
A process is an executing instance of an application, whereas a daemon is a background process not associated with a terminal session. Daemons typically start at boot and run as services.
What is the sed command used for in Linux?
sed (Stream Editor) is used for modifying files automatically or as part of a pipeline. It can perform basic text transformations on an input stream (a file or input from a pipeline). For example:
echo "hello world" | sed 's/world/Linux/'will output “hello Linux”.
What are runlevels in Linux?
Runlevels in Linux are modes that a Unix-based system operates in. Each runlevel has its own set of processes and daemons. Common runlevels include 0 (halt), 1 (single-user mode), and 3 (multi-user mode without graphical interface).
What is umask?
umask is a command used in Linux and Unix-like systems to set the default file creation permissions. For example, umask 022 sets the default permissions to 755 for new files and directories.
What is network bonding in Linux?
Network bonding involves combining two or more network interfaces into a single interface, providing redundancy or increased throughput.
What is SELinux?
SELinux (Security-Enhanced Linux) is a security architecture for Linux systems that allows administrators to have more control over who can access the system.
What is the purpose of the sudoers file in Linux, and how do you configure sudo access for users?
The sudoers file is used to control which users and groups can run commands as other users, groups, and as the superuser with the sudo command. Configuration is done by editing the /etc/sudoers file with the visudo command.
How do you change the ownership of a file or directory in Linux using the chown command?
Use the chown command followed by the new owner and the file or directory name. For example:
sudo chown username filenameHow do you recursively copy files and directories in Linux using the cp command?
Use the cp -R command to copy directories recursively. For example:
cp -R /source/directory /destination/directoryWhat is the purpose of the netstat command in Linux, and how do you view network connections and listening ports?
netstat is used to display network connections, routing tables, interface statistics, masquerade connections, and multicast memberships. For example, to view all active connections:
netstat -natpHow do you set up a static IP address in Linux using the command
-line interface?
Edit the network configuration file (e.g., /etc/network/interfaces or use nmcli for NetworkManager) and set the static IP configuration. For example:
iface eth0 inet static
address 192.168.1.100
netmask 255.255.255.0
gateway 192.168.1.1Then restart the network service.
How to copy a file to multiple directories in Linux?
Use a loop or xargs. For example, using a loop:
for dir in /path/to/dir1 /path/to/dir2; do
cp /path/to/file "${dir}"
doneHow do you start and stop a service in Linux?
Use systemctl to start or stop a service. For example:
sudo systemctl start nginx
sudo systemctl stop nginxHow do you troubleshoot a Linux system that cannot connect to a remote server?
Check basic connectivity with ping, ensure correct DNS resolution with dig or nslookup, check firewall settings, and validate SSH configurations if applicable.
What steps would you take to fix a network connectivity issue in Linux?
Confirm physical connections, use ip link to check interface status, ensure correct IP addressing with ip addr, check routing with ip route, and test connectivity with ping.
How do you check the system logs in Linux?
Use journalctl or view logs in /var/log/, such as /var/log/syslog or /var/log/messages, depending on your system configuration.
What are the possible reasons for a Linux system running out of memory?
Possible reasons include memory leaks in applications, insufficient swap space, or too many processes consuming all available memory.
How would you troubleshoot a slow-performing Linux server?
Check CPU load with top or htop, inspect disk I/O with iostat, review memory usage with free, and look at network traffic with iftop.
What does the ‘ifconfig’ command do in Linux?
ifconfig is used to configure, control, and query TCP/IP network interface parameters from a command-line interface, allowing you to activate or deactivate interfaces, assign IP addresses, set netmasks, and configure other options.
How do you set up a fixed IP address in Linux?
Similar to setting up a static IP, you would edit the network configuration files or use a network manager tool to assign a fixed IP.
How do you configure a DNS server in Linux?
Install and configure BIND or other DNS software, set up the necessary zone files, and ensure proper permissions and security settings are in place.
What is a firewall in Linux, and how do you set it up?
A Linux firewall can be configured using iptables or firewalld to allow or block traffic based on IP addresses, ports, and protocols. Configuration involves setting up rules that specify what traffic is permitted and what is blocked.
How do you check the network connectivity between two Linux systems?
Use ping to check basic connectivity. For more detailed analysis, use traceroute to see the path traffic takes between the two systems.
What is the purpose of the ‘route’ command in Linux?
The route command is used to view and manipulate the IP routing table in Linux. It allows you to add, delete, or modify routes to specific network destinations.
How do you configure a Linux system to act as a router?
Enable IP forwarding in the kernel, configure appropriate routing rules, and set up iptables or another firewall to handle NAT and packet forwarding.